
简介
cURL 是一个开源项目,主要的产品有 curl 和 libcurl: curl 是一个跨平台的 URL 命令行工具,libcurl 是一个 C语言的网络协议扩展库。两者都是基于多种互联网通用协议对指定 URL 的资源进行数据传输。更多的信息可以阅读电子书:《Everything curl》
GUN Wget 也是一个免费的开源项目,用于从 web 上下载文件。
wget 使用
通过软件管理包安装非常简单,可参考:《How to Install Wget in Linux》
# Ubuntu/Debian
apt-get install wget
# RHEL/CentOS/Fedora
yum install wget
# OpenSUSE
zypper install wget
# ArchLinux
pacman -Sy wget
安装完毕之后,可以使用 wget --version 或 wget -V 验证工具是否安装成功!
可以做什么?
- 通过
HTTP、HTTPS、FTP、FTPS协议递归下载文件 - 支持自动断点续传文件【
-c参数,旧版本可能存在问题,详情见:Linux 环境下使用 wget 命令下载 Blob 文件断点续传问题】 - 支持通配符批量下载文件
- 支持将下载的文档中的绝对链接转换为相对链接,以便下载的文档可以在本地彼此链接(–convert-links)
- 支持:HTTP 代理、COOKIE设置、HTTP 持久化连接
常用参数
更多参数,查看GNU Wget Manual,详细使用用法自行谷歌!
下载参数
| 选项/参数 | 作用 |
|---|---|
| -b, –-background | 启动后转入后台执行【可以通过 tail -f wget.log 查看下载进度】 |
| –progress=TYPE | 设置进程标记【通过 -b 后台作业进行下载时】 |
| -e, –-execute=COMMAND | 启动下载进程之前执行命令【如:设置临时环境变量…】 |
| -c, –-continue | 接着下载没下载完的文件【即:断点续传】 |
| -S, –-server-response | 打印服务器的回应 |
| -nc, –-no-clobber | 不要覆盖存在的文件或使用.#前缀【若本地已有同名文件,拒绝下载-在多次重复下载同一个站点时或者存在站点多个网页引用同一个资源时常用】 |
| -N, –-timestamping | 不要重新下载文件除非比本地文件新【只是单纯的对比下载时间,并不会理会本地文件是否下载完整】 |
| -t, –-tries=NUMBER | 设定最大尝试链接次数(0 表示无限制).【当由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕,可以设置最大尝试连接次数】 |
| -T, –-timeout=SECONDS | 设定响应超时的秒数 |
| -w, –-wait=SECONDS | 指定两次重试之间间隔秒数 |
| –waitretry=SECONDS | 在重新链接之间等待的秒数 |
| –random-wait | 在下载之间等待 0-2 秒 |
| -Y, –-proxy=on/off | 打开或关闭代理【更推荐:https://www.cnblogs.com/frankyou/p/6693256.html 文中方法3】 |
| -Q, –-quota=NUMBER | 设置下载的容量限制【注意:这个参数对单个文件下载不起作用,只能递归下载时才有效。如:-Q=5m】 |
| -–limit-rate=RATE | 限定下载输率【即:限制下载带宽,如:--limit-rate=50k】 |
| –-bind-address=ADDRESS | 指定本地使用地址(主机名或IP,当本地有多个IP或名字时使用) |
| –-spider | 不下载任何东西【当需要调试打印 HTTP 响应信息时会使用该参数跳过下载步骤】 |
下载路径设置
| 选项/参数 | 作用 |
|---|---|
| -O FILE, –-output-document=FILE | 把文档写到文件中【即:自定义下载路径】 |
| -nd, –-no-directories | 不创建目录(缺省参数) |
| -x, –-force-directories | 强制创建目录【如:下载 www.learningcontainer.com/wp-content/uploads/2020/05/sample-mp4-file.mp4 会层层创建目录】 |
| -nH, –-no-host-directories | 不创建主机目录【当 -x 参数存在时才可用】 |
| -P, –-directory-prefix=PREFIX | 将文件保存到目录 PREFIX/… |
输入/记录日志输出
| 选项/参数 | 作用 |
|---|---|
| -i, –-input-file=FILE | 下载指定文件中出现的URLs |
| -F, –-force-html | 把输入文件当作HTML格式文件对待 |
| -B, –-base=URL | 将URL作为在-F -i参数指定的文件中出现的相对链接的前缀 |
| -d, –-debug | 打印调试输出 |
| -q, –-quiet | 安静模式(没有输出,下载完成直接退出) |
| -v, –-verbose | 冗长模式(这是缺省设置) |
| -nv, –-non-verbose | 关掉冗长模式,但不是安静模式【相比安静模式,该模式下若下载完成会输出下载完成信息】 |
| -o, –-output-file=FILE | 把记录写到文件中 |
| -a, –-append-output=FILE | 把记录追加到文件中 |
HTTP 选项参数
| 选项/参数 | 作用 |
|---|---|
| –-no-cache | 允许/不允许服务器端的数据缓存 (一般情况下允许) |
| -–no-http-keep-alive | 关闭 HTTP 活动链接 (持久链接) |
| -–http-user=USER | 设定HTTP用户名 |
| -–http-passwd=PASS | 设定HTTP密码 |
| -–proxy-user=USER | 设定代理的用户名 |
| -–proxy-passwd=PASS | 设定代理的密码 |
| -U, –-user-agent=AGENT | 设定代理的名称为AGENT(默认为:Wget/VERSION |
| -–header=STRING | 在headers中插入字符串 STRING |
| –-load-cookies=FILE | 在开始会话前从文件中加载cookie |
| -–save-cookies=FILE | 在会话结束后将 cookies 保存到文件中 |
| -–referer=URL | 在HTTP请求中包含 Referer: URL头 |
FTP 选项参数
wget -v --ftp-user=demo --ftp-password=password "ftp://test.rebex.net/readme.txt"
递归下载
| 选项/参数 | 作用 |
|---|---|
| -r, -–recursive | 递归下载--慎用! |
| -l, -–level=NUMBER | 最大递归深度 (inf 或 0 代表无穷) |
| -k, –-convert-links | 转换非相对链接为相对链接 |
| -K, –-backup-converted | 在转换文件X之前,将之备份为X.orig |
| -m, –-mirror | 等价于 -r -N -l inf -nr【对网站做镜像下载】 |
| -L, –-relative | 仅仅跟踪相对链接 |
| -np, –-no-parent | 不要追溯到父目录 |
| -A, –-accept=LIST | 分号分隔的被接受扩展名的列表 |
| -E, –adjust-extension | 以合适的扩展名保存 HTML/CSS 文档 |
| -H, –span-hosts | 递归下载时,允许递归检索第三方外链域名【慎用!!!】 |
| -R, –-reject=LIST | 分号分隔的不被接受的扩展名的列表 |
| -D, –-domains=LIST | 分号分隔的被接受域的列表 |
| –-exclude-domains=LIST | 分号分隔的不被接受的域的列表 |
| –-follow-ftp | 跟踪HTML文档中的FTP链接 |
| –-follow-tags=LIST | 分号分隔的被跟踪的HTML标签的列表 |
| -I, –-include-directories=LIST | 允许目录的列表 |
| -X, –-exclude-directories=LIST | 不被包含目录的列表 |
案例:使用wget下载网站下所有的图片
图片命名有规则
对于命名有规则的图片,下载非常简单:使用通配符(*-任意长度的任意字符、?-任意一个字符、[]-括号中的任意一个字符、{..}-表示一个序列)下载即可
wget -b http://aliimg.changba.com/cache/photo/{260929610-260939610}_640_640.jpg
图片命名无规则
一共 22 页,图片全部在 CDN:img1.446677.xyz上,图片命名是非规则的!
- 遍历当前页面的
img.446677.xyz域名,下载资源 - 遍历 22 分页:
https://www.kanxiaojiejie.com/page/{1..22}
wget -b -c -r -H -D "img1.446677.xyz" -R "www.kanxiaojiejie.com" -nc https://www.kanxiaojiejie.com/page/{1..22}
curl 使用
cURL你想要了解的curl的知识基本都在:《Everything curl》里面。关于安装,请查看GET cURL。
可以做什么?
curl 的定位是在网络中“传输数据”,相比于wget的只能下载资源就显得curl的功能要强大太多了,而且其支持协议也比wget要多的多。curl 可以用来发送邮件、批量请求、下载文件、模拟表单提交、分析网站请求耗时…wget能做的,curl都能做!
常用选项参数
标准错误输出
| 选项/参数 | 作用 |
|---|---|
| -V, –version | 显示版本号并退出 |
| -v, –verbose | 展示资源传输详细信息 |
| –trace |
将调试跟踪信息写入到文件中 |
| –trace-ascii |
类似于 –trace,但没有十六进制输出 |
| -s, –silent | 静音模式-不显示任何标准错误信息(注意:不影响结果输出到stdout) |
| -I, –head | 只显示响应头信息 |
| -D, –dump-header <文件名> | 将响应头文件写入指定文件 |
| -i, –include | 在输出中包含协议响应头:Response Header + Body |
| -w, –write-out <format|@format-file> | 完成后使用输出格式 |
标准输出
| 选项/参数 | 作用 |
|---|---|
| -o, –output |
将输出写入文件(注意需要绝对路径)而不是stdout |
| -O, –remote-name | 将输出写入与远程文件同名的文件中,如:curl -O xxx/a.html 写入本地 a.html中 |
| -J, –remote-header-name | 使用头提供的文件名。如:Content-Disposition: attachement; filename=rustup-setup.exe |
!!!注意:
curl -O https://www.baidu.com请求只有域名部分或结尾以/结尾,请求是会报错的!这正是-o和-O的不同之处
输入
| 选项/参数 | 作用 |
|---|---|
| –limit-rate |
限制传输速度,模拟慢网络 |
| –cert |
携带客户端的SSL证书进行请求 |
| -k, –insecure | 使用SSL时允许不安全的服务器连接(忽略SSL验证失败) |
| -L, –location | 遵循重定向,自动处理重定向跳转 |
| -C, –continue-at |
指定断点续传的便宜量【!!!注意:要自动续传的话要使用 -C -,否则要自行指定】 |
| -m, –max-time <秒> | 允许传输的最长时间 |
| –connect-timeout <秒> | 允许连接的最长时间 |
| -x |
使用代理 |
请求
| 选项/参数 | 作用 |
|---|---|
| -0, –http1.0 | 使用 HTTP 1.0 版本协议 |
| –http1.1 | 使用HTTP 1.1 |
| –http2 | 使用HTTP 2 |
| –http2-prior-knowledge | 使用HTTP 2而不使用HTTP/1.1升级。 |
| –http3 | 使用HTTP v3 |
| -X, –request <命令,如:POST/GET/PUT…> | 指定要使用的请求命令 |
| -G, –get | 将数据放入URL 中,并使用GET发送请求 |
| -d, –data | HTTP 要传输的数据,默认是POST |
| –data-urlencode | 将HTTP请求数据进行URL编码 |
| -F, –form <key-name=content> | 指定多部分MIME数据、数据类型。如:模拟POST表单上传二进制文件 |
| -T, –upload-file |
使用PUT方式传输本地文件到服务器-一般FTP上传文件 |
| -H, –header <header/@file> | 将自定义头传给服务器 |
| -A, –user-agent |
发送User-Agent: <name>到请求头中 |
| -e, –referer |
设置Referer: <url>到请求头中 |
| -b, –cookie <data|filename> | 从字符串/文件发送cookie |
| -c, –cookie-jar |
操作后将cookie写入文件名 |
| -u, –user |
服务器用户和密码 |
使用curl变量格式化输出
重定向输出
- %{stderr} - 使用
-w参数格式化结果时,将该变量后的结果作为标准错误-stderr输出 - %{stdout} - 使用
-w参数格式化结果时,将该变量后的结果作为标准输出-stdout输出
获取请求信息
- %{local_ip} 本地客户端IP地址(支持
IPv4或IPv6) - %{local_port} 本地客户端请求端口
获取响应信息
- %{content_type} 获取
HTTP响应头中的Content-Type - %{method} 最终一次
HTTP请求方法 - %{http_version} 最终一次
HTTP请求的协议版本 - %{scheme} 获取最终
URL的通信协议方式(若使用了-L参数,发生了重定向跳转最终获得的值可能和你预想的URL协议不一致) - %{response_code} 最后一次传输返回的数字响应码(如:
HTTP CODE-旧版本获取响应码%{http_code}) - %{url_effective} 获取最终重定向后的
URL地址(-L参数设置URL自动重定向跳转,而不是直接返回 301/302 信息) - %{num_redirects} 重定向次数(只有使用了
-L选项且确实发生了重定向该值才为非0) - %{redirect_url} 重定向之后的
URL(当没有设置-L参数时才有值) - %{remote_ip} 远程IP地址(支持
IPv4或IPv6) - %{remote_port} 远程响应端口
- %{ssl_verify_result} SSL 证书验证结果:0-成功
- %{filename_effective}
curl写入的最终文件名。只有当使用了--remote-name或--output选项时这个选项才有意义。它与--remote-header-name选项结合使用时最有用 - %{ftp_entry_path} 登录到远程FTP服务器时,
curl的初始路径 - %{num_connects} 最近一次请求传输建立的TCP连接数
传输速率
- %{size_download} 下载内容的总字节数(即:
Body总字节数-Content-Length) - %{size_header}
HTTP响应头headers的总字节数(不包含Body体) - %{size_request}
HTTP请求中发送的总字节数 - %{size_upload} 上传的总字节数
- %{speed_download}
curl的平均下载速度,单位:字节/秒【B/s】 - %{speed_upload}
curl的平均上传速度,单位:字节/秒【B/s】
请求时间
- %{time_appconnect} 从“发起请求–>完成SSL/SSH 等上层协议”所耗费的时间,单位-秒
- %{time_connect} 从“发起请求–>完成TCP三次握手”所耗费的时间,单位-秒
- %{time_namelookup} 域名解析完成所耗费的时间,单位-秒(测试
DNS服务器的寻址能力) - %{time_pretransfer} 从开始到文件传输即将开始所花费的时间(所有传输前的命令和特定协议的协商),单位-秒
- %{time_redirect} 所有重定向所耗费的时间(重定向域名寻址–>准备传输前),单位-秒
- %{time_starttransfer} 过程“发起请求连接–>接收到服务器的第一个字节响应”所耗费的时间(包括:请求/响应过程链路连接的耗时+服务器处理逻辑耗时),单位:秒
- %{time_total} 整个请求操作的总耗时(发起请求连接–>传输完毕),单位:秒
案例:使用curl分析网站单次请求响应情况
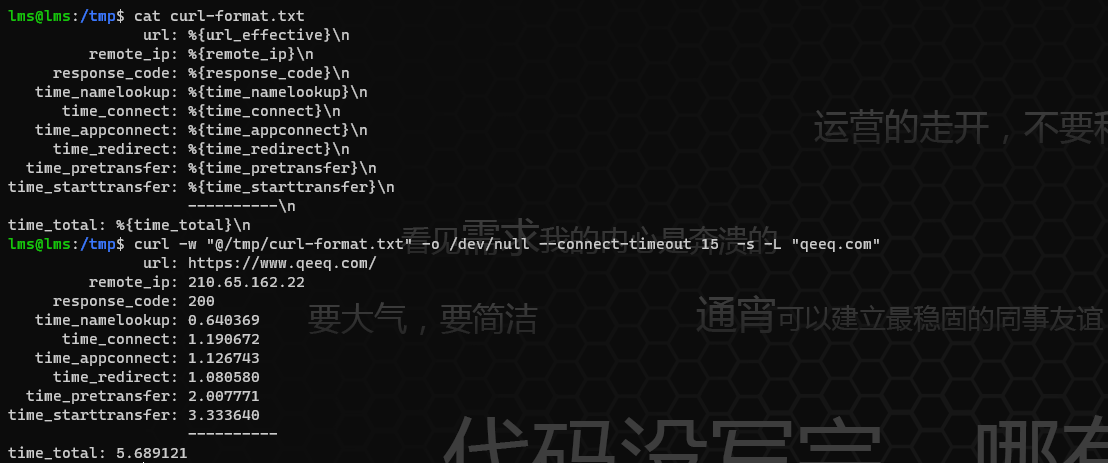
先准备一份格式化文件curl-format.txt,内容如下:
# cat curl-format.txt
url: %{redirect_url}\n
remote_ip: %{remote_ip}\n
response_code: %{response_code}\n
time_namelookup: %{time_namelookup}\n
time_connect: %{time_connect}\n
time_appconnect: %{time_appconnect}\n
time_redirect: %{time_redirect}\n
time_pretransfer: %{time_pretransfer}\n
time_starttransfer: %{time_starttransfer}\n
----------\n
time_total: %{time_total}\n
示例:
# curl -w "@/tmp/curl-format.txt" -o /dev/null --connect-timeout 15 -s -L "qeeq.com"
url: https://www.qeeq.com/
remote_ip: 210.65.162.22
response_code: 200
time_namelookup: 0.640369
time_connect: 1.190672
time_appconnect: 1.126743
time_redirect: 1.080580
time_pretransfer: 2.007771
time_starttransfer: 3.333640
----------
time_total: 5.689121
总结
| 特性 | wget | curl |
|---|---|---|
| 作用 | 下载文件 | “资源传输” |
| 开源 | 是 | 是 |
| 支持协议 | HTTP, HTTPS, FTP, FTPS | 基本的网络通用协议都支持(支持30多种协议) |
| 可交互 | 否 | 否 |
| 是否支持递归下载 | 是 | 否 |
| 跨平台 | 不支持 X-Windows | 支持跨平台客户端 |
| 使用难易 | 简单,可配置少 | 功能丰富,可自定义的配置多,有一定的使用门槛 |
- 两者都是不可以交互的命令行工具,这意味着
wget和curl都可以直接在Shell脚本、crontab等工具中被使用 wget是一个无需依赖其他扩展的独立、简单的程序,专注于下载且支持递归下载,如果遇到访问链接301、302等情况会自动进行跳转然后进行下载curl是一个功能完备的网络请求工具-更多的用途是:从stdin读取数据将网络请求结果输出到stdout。更多的协议、提供了更大的自定义操作功能,如:并发测试、下载数据、上传数据、获取响应报头进行分析…!【curl -L参数可以实现重定向自动跳转】
下载文件:优先使用
wget,其余情况使用curl
最后可以看一下:《10个例子教你学会wget命令》、《curl使用实例》、21 个 curl 练习 实战练习一下!或者可以写一个脚本并发请求百度页面分析每个请求的报头信息。





