
乱码的原因:操作系统、输入流、输出流、输出承载展示工具 这几方有其中一项或多项的编码与其他不一样,从而导致了对于同一个字符用了不同编码来解析导致的。
一般来说,只要:输入编码、输出编码是一样的,那么就不会产生乱码。
周末遇到了 IDEA 输出中文乱码的问题,以前也遇到过…但是都属于零散记录在有道中,依然是弄了一大晚上。趁此机会将这些小知识点整理记录一下,理解一些“乱码”的原因。
local(系统区域设置)、字体、LANG(系统语言) 的区别
locale 指的的是当前操作系统的语言环境,如:你当前系统是用中文、英文、还是泰文,但要注意这仅仅是你当前系统本身的语言环境,跟你通过浏览器上网能否正常浏览中文、英语、法语这些没有直接关系。在 Linux 下,所有支持的语言环境配置都放在 /usr/share/i18n/locales 目录下
fonts 指的是字体。假如我当前将系统语言设置为英语的语言环境,那我浏览一个中文网站是不是就不能浏览或者是乱码了呢?这显然是不合理也不利于网络传播的。
具体的过程如下:网页内容通过网络传输到我们的电脑上以后,浏览器自身会根据网页中设定的字符集编码(若没有设定,则浏览器自身进行相应判断),根据网 页采用的字符集,在用户计算机本地操作系统的字体库中寻找合适的字体,然后通过文字渲染工具把相应的文字在屏幕上显示出来。
因此,虽然我们指定了系统的语言环境,但是我们可以发现操作系统本身依然会安装很多字体文件(Windows 系统在 C:\Windows\Fonts 文件夹下;Linux 系统在 /usr/share/fonts 文件下)。一般常见的字体文件格式有 *.ttf - TrueTypes字体文件, *.ttc - TrueTypesCollection字体文件(ttc文件实际是 Microsoft 开发出来的一种新字体格式标准,其实就是多个ttf文件的合集,共享同一笔划信息,可以有效地节省了字体文件所占空间,增加了共享性)。
上面还提到了一个字符集编码的概念。在 Linux 下,所有的字符集编码方式都放在 /usr/share/i18n/charmaps 目录下
==总结:locale 决定了你看到的系统习惯以及能输入什么语言;而字体是将对应语言渲染出来的载体==
# Windows 下通过 powershell 获取语言环境
Get-Host
Get-UICulture
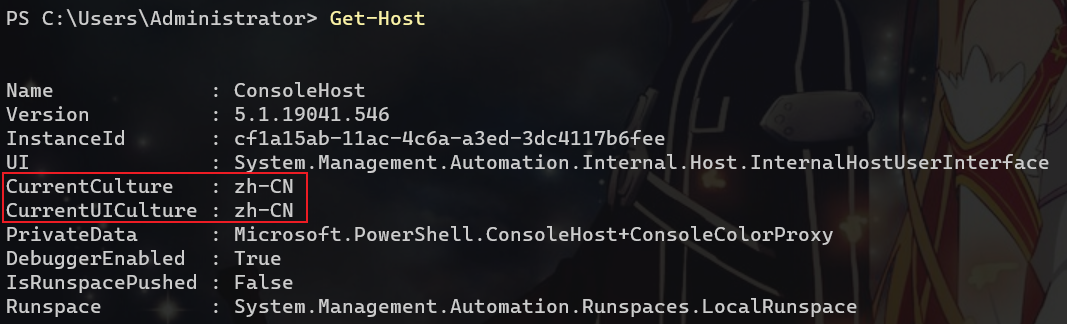
# Windows 获取(设置)编码字符集:https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/chcp
chcp
| Code page | Country/region or language |
|---|---|
| 936 | 中国 - 简体中文(GB2312) |
| 949 | 韩文 |
| 950 | 繁体中文(Big5) |
| 1200 | Unicode |
| 1201 | Unicode (Big-Endian) |
| 52936 | 简体中文(HZ) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |

$ locale
LANG=zh_CN.UTF-8 # 语言
LC_CTYPE="zh_CN.UTF-8" # 语言符号及其分类
LC_NUMERIC="zh_CN.UTF-8" # 数字
LC_TIME="zh_CN.UTF-8" # 时间
LC_COLLATE="zh_CN.UTF-8" # 比较和排序习惯
LC_MONETARY="zh_CN.UTF-8" # 货币单位
LC_MESSAGES="zh_CN.UTF-8" # 提示信息及菜单信息等
LC_PAPER="zh_CN.UTF-8" # 默认纸张尺寸大小信息
LC_NAME="zh_CN.UTF-8" # 姓名书写方式
LC_ADDRESS="zh_CN.UTF-8" # 地址书写方式
LC_TELEPHONE="zh_CN.UTF-8" # 电话号码
LC_MEASUREMENT="zh_CN.UTF-8" # 度量衡表达方式
LC_IDENTIFICATION="zh_CN.UTF-8" # 对locale自身包含信息的概述
LC_ALL=
# 优先级:LC_ALL > LC_* > LANG
IDEA Java 输出控制台中文乱码
1、 查看操作系统的编码
Windows + R 输入 cmd,打开 DOS 窗口,在命令行工具输入 chcp 查看当前系统默认设置的系统cmd > chcp
- 936-GBK
- 65001-UTF8]
2、 查看 IDEA 控制台的编码
一般默认是 CMD 或者 Powershell 工具,只要设置了系统的编码为 UTF-8 之后,CMD/PowerShell 的编码就会变成 UTF-8
如果是 Git Bash,则通过 解决 Git Bash 在 windows 下中文乱码的问题 处理
3、 查看文件的编码方式
通过“记事本”程序 或 IDEA 打开你的代码文本文件,查看编辑器右下方的文件编码,将文件改为 UTF-8 再进行保存
4、 查看 IDEA 的 Font 、File Encodings
字体支持:一般来说绝大部分字体都是支持中文的,可以简单看一下:File > Settings > Editor > Font ,如果不确定自己的字体是否支持中文的,就选择微软雅黑吧。
文件编码:File > Settings > Editor > File Encodings,然后将:Global Encoding、Project Encoding、Properties File 都设置为 UTF-8
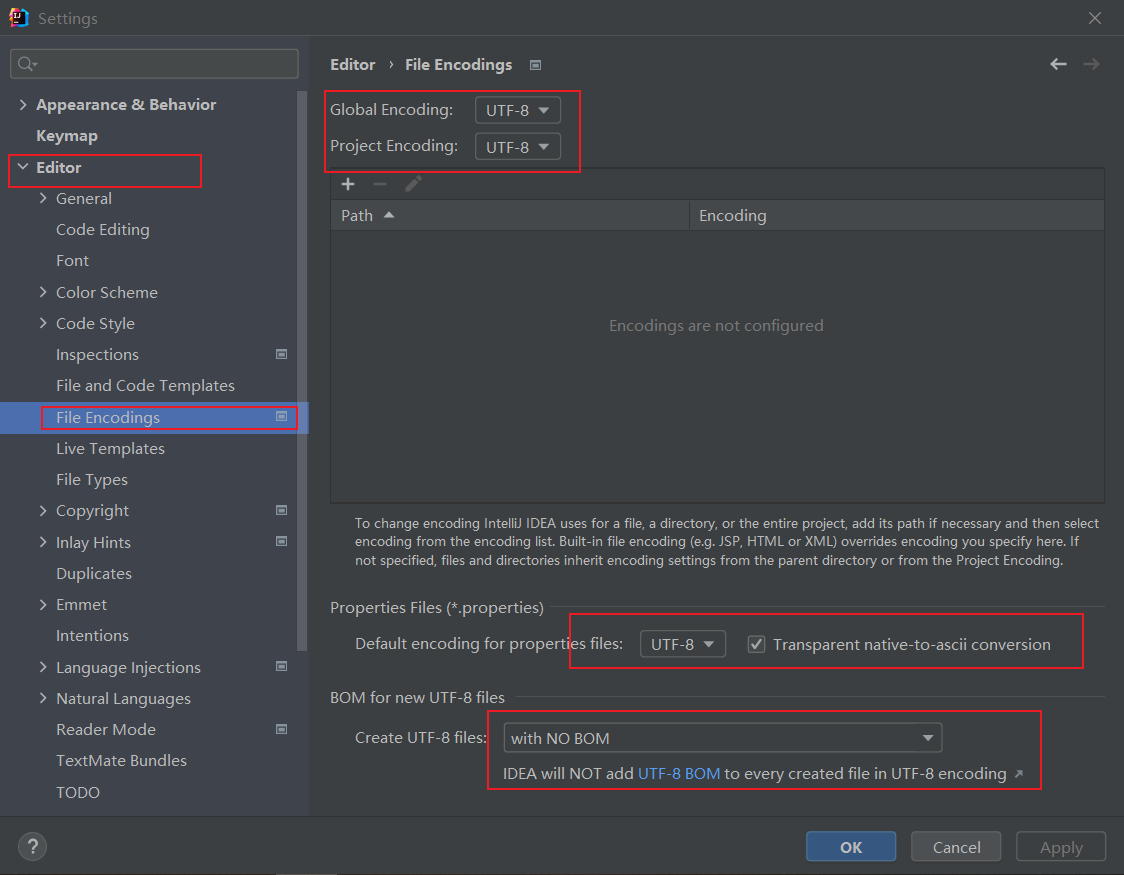
一般来说,以上设置之后应该就可以了。如果仍然是乱码,那么查看当前 Project 目录下的 .idea 中的 encodings.xml 文件,看一下是不是项目编码的缓存没有更改过来。如果此处不是显示 UTF-8,将该文件删除,关闭编辑器然后重新打开令其重新生成即可。

5、 设置 IDEA 的 vmoptions
打开 IDEA 的安装目录,在 bin 目录下有idea.exe.vmoptions 或 idea64.exe.vmoptions 文件。
或者可以通过:打开 IDEA 编辑器,然后菜单栏选择 Help > Edit Custom VM Options 会自动打开 vmoptions 文件。在文件末尾新增行添加:-Dfile.encoding=utf-8,然后重启编辑器,再次查看中文是否乱码。
此时可能会出现:通过 logger 写入到文件的中文不是乱码,但是 System.out.println() 输出的中文仍然乱码。
查看是否手动设置了 Tomcat VM options 或 Spring Boot VM options,将 -Dfile.encoding=UTF-8 加上
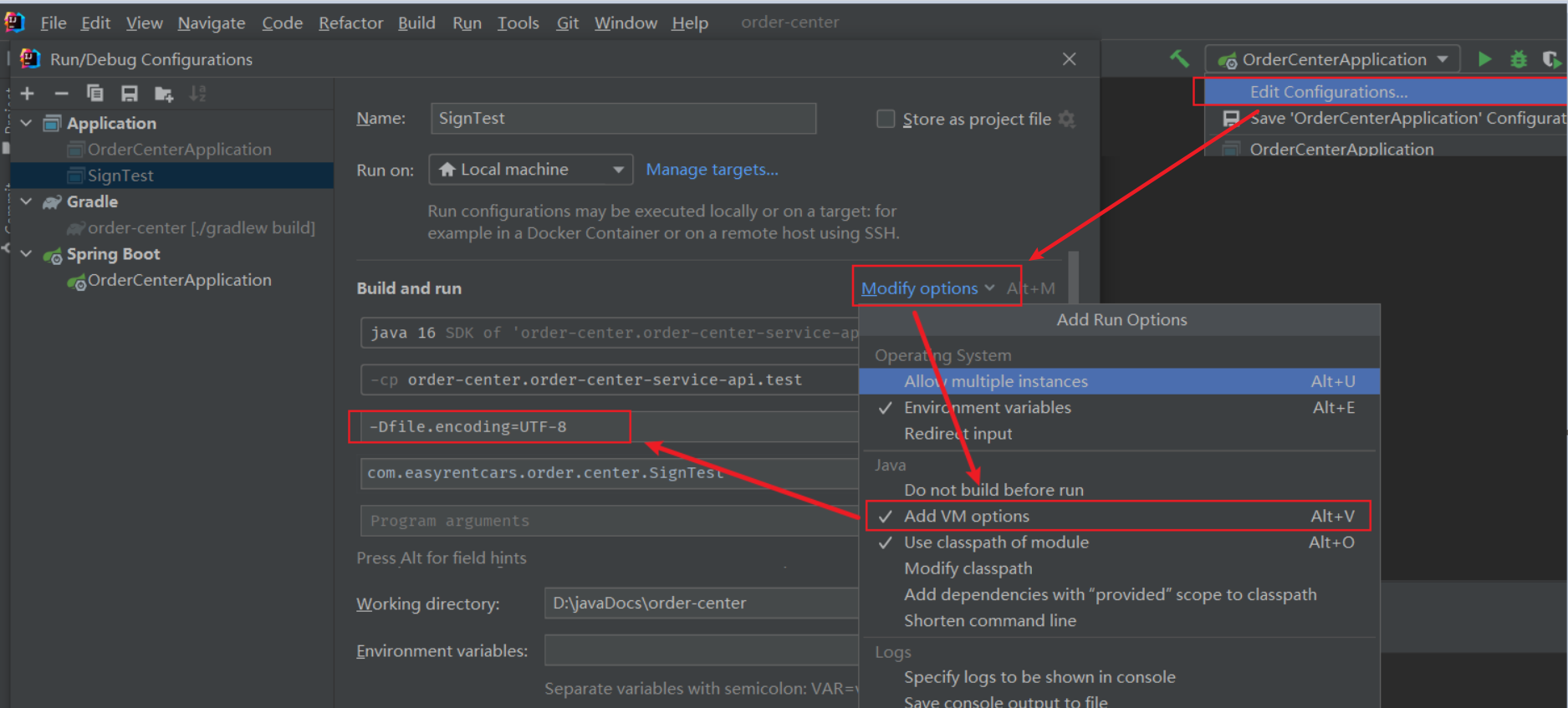
设置完,重启编辑器查看是否有效。
6、 如果仍然没有效果,尝试重新安装 IDEA。这是最无解的操作…不过在操作中确实是有效的,莫名其妙可以。若仍然不行,希望你解决了之后能告诉我一下~谢谢





