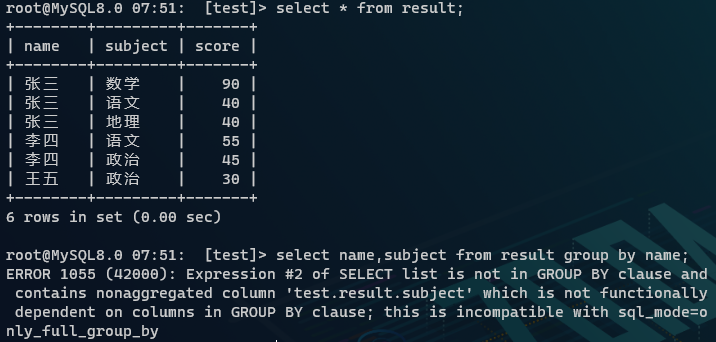
文中涉及的数据表见文章:SQL DML 语句简介
GROUP BY 查询子句可以根据给定列(该列称为:聚合列)的值对数据集进行分组,一般会结合聚合函数或聚合分析函数最终得到一个分组汇总表。
聚合函数是将组中的行汇总计算为单个值的函数,如:COUNT()-计算行数、SUM()-求和、AVG()-求平均值、MAX()-取集合中的最大值、MIN()-取集合中的最小值…等
需要注意的是:
- 严格模式下:当
SELECT语句配合GROUP BY子句一起使用时,SELECT的列、HAVING子句的列、ORDER BY的非聚合函数列都必须要出现在GROUP BY列中(即:在使用GROUP BY语句时,非聚合列只有使用了聚合函数才能在SELECT列中) - 宽松模式下:如果非聚合列和聚合列是一一对应,那么得到的汇总结果是正确的,但是:若非聚合列和聚合列不是一一匹配时,非聚合列出现的值是随机不准确的
因此:工作中,sql_mode 一般我们都会设置为严格模式 ONLY_FULL_GROUP_BY!对问题的详细描述可以看官方文档-《MySQL Handling of GROUP BY》,或参考博文:《神奇的 SQL 之层级 → 为什么 GROUP BY 之后不能直接引用原表中的列》,深究可以学习一下集合论再去查看:《SQL基础教程》、《SQL进阶教程》书籍。
总的来说:GROUP BY 是按照某一列或几列进行“分组”查询,查询的信息必须是分组的依据或“组”属性信息。如:根据学生身高和性别进行分组,你只能得到这个组里身高、性别的分组信息,或者得到最高的身高、各自组有多少人等这类分组依据及组属性信息,但是不能一步到位的得到这个组里最高身高的男生是谁这类明确到具体组员的非分组依据信息!